
The costs and benefits of Interfaces.
Introduction
I’m a fan of interface driven development in Delphi, and I am not quiet about that. Like any syntax feature however, it’s important to understand both the benefits, and the costs of the feature. Interfaces have several great benefits, but of course they also come with costs.
Today, I’m going to share my experiences of working with interfaces, and justify the reasons that I still love using them.
The Features
I’m not going to spell out exactly what interfaces are here. I expect that if you’re reading this, you already have some idea what interfaces are, and if that is not the case, I encourage you to read up on that first. Instead, I’m going to briefly spell out the key features of working with interfaces, because they can differ among programming languages. In particular, I’m describing the features of interfaces as they are implemented in Delphi, the programming language with which I am most familiar.
One thing which is common to all implementations of interfaces is that they may have multiple implementations. Many would argue that if you’re not using multiple implementations, then there is no point to using interfaces at all. I would argue (and I’m about to), that while multiple implementations is certainly the defining feature of interfaces, it is not the most critical reason to use them, and that you ought to consider using them even if you have only a single implementation. More on this in a moment.
Another key feature, and the one that I do think matters most, is that of contract imposition. When you work with interfaces, the interface imposes a contract on its implementations. This is a key defining feature of interfaces also, as it ensures that an implementation does what is expected (within reason). The idea being that when you can see the interface, you’ve no need to go looking at the implementation in order to know how to work with the code, but instead can simply infer its behavior from the interface.
Finally, though this is where compilers may differ, in the Delphi programming language, using interfaces means that you’re working with Automatic Reference Counting (ARC), in that references to interfaces are counted. The Delphi programming language isn’t naturally ARC based, though there were attempts to move it to the ARC model some time back, it was determined that doing so would be too much work and wreak too much havock on the existing user community, and so the decision was reversed. Interfaces however, have always been ARC in Delphi, and so if this is the memory model that you would like to use, then interfaces are your only compiler provided option.
The Costs – Indirection
Everything that your compiler does for you, involves cost. Interfaces have quite a significant cost because of something called the VMT (Virtual Method Table). For the sake of the uninitiated, what is a VMT?
Well, if you’ve read this far and are familiar with interfaces, then you’ll also be familiar with OOP (Object Oriented Programming), and will most likely have written objects and classes already. You’ll also be familiar with inheritance. When you write a class which descends some other class, you have the opportunity to “override” methods on the base class.
In order to enable this functionality for you, the compiler creates a table of pointers to the methods of a class, and when you descend and override those methods, a second table is created for your descended class, with the pointers altered to point at the overridden methods. Barring the minor semantics, such as inlining and other optimizations, this is essentially how this functionality is implemented in all compilers that I’m aware of.
Virtual Method Tables impose a performance penalty on your code. You see, as your CPU blisters along executing your code, when it encounters a method call, it can’t simply jump to that methods code, it first has look up where the method is from the VMT. This is called indirection, and while modern CPU’s have become quite good at handling indirection with their instruction prediction systems, it remains slower than direct function or procedure calls. In terms of optimization, VMT’s are quite costly.
Interfaces worsen the costs of indirection. Because interfaces support multiple implementations, and because those implementations themselves will each have different VMT’s. When the CPU encounters a method call on an interface, it must first determine which VMT it should look at, then look up the method location, and then jump to that.
I decided to perform some benchmark tests on my interface VMT based code, and code using static methods, to see the difference. I don’t want to drift into the weeds of performance benchmarks here, so please take this as illustrative rather than as solid numbers, but here are my results…
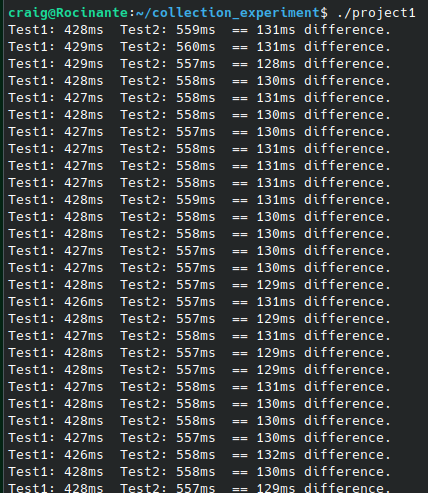
In the image, Test1 measures the static code and Test2 measures the virtual function code. As you can see, the virtual code averages around 130ms slower than the static code. This is based on writing 100,000,000 integers to a list, and reading them back to perform a summation. The test in each case, covered a simple for loop to set the values, and another to sum them, and measured only those actions. The allocation of memory was placed outside the test measurement.
So, a 130ms difference over 100 million entities may not seem like much, but if your entire code base depends on virtual methods (as most code bases today do), or if found in a performance critical region of the code, these costs can be quite significant. As an example, imagine this were the case in the rendering loop for a video game, at 60 frames per second. 130 milliseconds is, if I’ve done the arithmetic correctly, around 8 frames. Gamers are going to be at least a little upset at getting 52fps rather than 60fps – and of course, this cost adds up with every indirection used.
The Costs – ARC
Delphi’s interfaces use Automatic Reference Counting, which imposes another potential performance cost. You see, any time an interface reference drops out of scope, the compiler injects code to reduce the reference counter, and to dispose of the objects memory allocation when the counter reaches zero. To make matters worse, I’ve never yet encountered a compiler that supports ARC which doesn’t also support “weak” references. I have strong views on weak references that I won’t delve into here, but suffice to say that I feel compilers never should have implemented weak references as a feature of ARC memory management. My strong opinion here is not, as you might expect, based on the performance cost of weak references, but the performance cost is worth mentioning here.
For the sake of the uninitiated, a weak reference in ARC is a reference which does not contribute to the reference count of an object, but which must be set to nil (or otherwise invalidated) when the object that it references is disposed. In order to accomplish this, the compiler injects code to retain a list of weak references to an object. At the point that the object is disposed, the compiler injects the code to iterate the weak reference list, and to set those references to nil. I did not take the time to benchmark this, but instead ask you to take my word for it, this is a performance cost – it’s really just “laws of physics” here, if the cpu has more work to do when disposing of an object, that work costs cycles.
The Costs – So much more typing!
Another cost of interfaces, which you’ll know well if you’ve had any serious experience in using them, is the sheer amount of red-tape typing added by their use. In any programming language, interfaces add at least a little extra typing because you must declare the interface it’s self, before you type out an implementation. In Delphi, things are much worse.
Since the early days of object oriented Pascal, the language has involved more typing than comparable languages, because Pascal is very formal. It’s clear to me however, that from the earliest days, Pascal was already thinking from the perspective of separating interface from implementation. It’s literally a part of the language for units, the words “interface” and “implementation” are reserved words. Classes are implemented by first writing their declaration in the “interface” section of a unit source code, and then their definition is placed in the “implementation” section. Classes are already more work, from a sheer typing perspective, in Delphi pascal than in most other programming languages.
Interfaces add yet more typing in Pascal, and it does feel a little redundant. First you type out the interface it’s self, and then the declaration and definition parts of a class which implements that interface. “Trust me bro” As someone that uses interfaces heavily in their code, I can tell you that this is a labor.
This is made a little worse with the use of properties. Properties are, as “ThePrimagen” puts it, “a lie.”
Delphi’s interfaces support properties, which is essentially a syntactic sugar coating over writing methods to get or set values. The problem with interfaces is that there is no way to provide direct access to the backing storage behind a property (as there is with classes), and so it becomes necessary to always write the getter, or setter, or both methods in order to gain access to data. If you like the syntactic sugar of properties, you get yet more typing to do – yay!
So why use Interfaces? – On Performance.
With a performance penalty, and the extreme amount of extra typing to do in order to use interfaces, you may well be wondering why I’d use them so much. I mean, this is a kind of craziness right?
Well, if I’m going to persuade you that interfaces are worth the effort, then I have only two approaches. The first would be to somehow mitigate the costs of using them, and the second would be to justify those costs. I’m going to take the second of these approaches, but I can’t do that effectively without at least partially tackling the performance concerns.
This is where I am going to tread delicately. I would not want you to think that I’m making an argument that performance doesn’t matter, it absolutely does matter. I’ve seen quite heated debates about performance, and while I have some strong opinions, that’s not what this article is about. So as to not get too deep into the weeds on this subject, I must give some rather sweeping statements that I don’t fully believe, lest I go into too much detail. So lets start with this one.
“Performance doesn’t matter until it does.”
I know that you’re most likely feeling the uncomfortable itch that the above statement induces, but give me a moment to explain my position on this. There’s a very old argument in the performance debate that computers are fast enough to account for any ill-performing code that the developer might write. This is fundamentally not true. In my performance benchmark above, I showed a loss of around 130ms doing nothing more than summing a large number of integers. If you were to use an interface driven, generic list collection class, as I did in that benchmark, for every list in your application, complete with all the extra processing you might want to do on each item, then you could very quickly consume all of the available CPU cycles within the target time frame of your application process.
To put it more simply, say your application is running a report and your end user expects that report to run in just a few seconds. Depending on the volume of data to be processed into the report, a few milliseconds over many iterations could add up fast. No end user wants to wait hours, or even minutes to view a report. When your competitors product shows this report in seconds, but your software takes minutes, you’re already at high risk of losing a customer. I say this to explain that I do understand that performance does matter, except of course, that it doesn’t…
This is where the old argument of “make it work, then make it fast” comes from. If using the interface driven generic list makes a total difference of 130ms to the run time of your report, no customer is going to mind that, it’s a barely perceptible period of time. The reason that performance debates become so heated is that those in favor of optimization are concerned with the cumulative impact of performance costs, while those against optimizing too early are more concerned with the “big picture”, the result of the performance cost on a particular action of the software. The opposing views here are typically based on the experiences of the person making the argument. A video game developer is going to tell you that every cycle counts, while a line of business application developer might be more concerned with overall action time. Each use case is it’s own case.
I don’t fall down on either side of this argument, and neither should you. When you pick a side in this debate, you’re already wrong. In order to approach software performance in a rational way, you must accept that in some use cases performance is critical, and in others it’s not. If you’re talking about a large scale web service, such as those provided by social media giants or streaming media services, then every CPU cycle really does count. So much so that such companies will invest huge amounts of money in optimizing or even rewriting swathes of their code base to save a few CPU cycles here and there. On the flip side, if you’re writing a line-of-business management product, say, an inventory system for retail, or an asset tracking system, well then a cost of a few hundred milliseconds over 100 million items is likely perfectly acceptable.
Given that the majority of software today is written under an object oriented programming model (something that I actually feel is a mistake by the way), we’re already dealing with the performance penalties of using indirection in the form of VMT’s. The additional performance cost of using an interface with it’s multiple VMT approach is really not very significant at all, it’s on nano-second scales. In the majority of cases, outside those cases in which performance is critical, the costs aren’t particularly relevant.
My final word on performance is that the use of interface driven code is far from being the first place that you should even look for performance gains. I mentioned social media giants above, stating that they’re spend huge amounts of money and time on optimization. Well, this is true, but take a look at what some of those companies have done to improve the performance of their code and you might notice a pattern. Facebook moved from interpreted PHP and Javascript code to native binaries, both on their back end, and for their mobile apps. Uber did the same. Twitter, the same. Most of the giant organizations that we see spending money on re-writes, did so to move from slower languages to faster ones. I don’t have access to their source code to look, I only have their public announcements to go on, but my guess is that as they moved from interpreted languages to binary native languages, they kept with an object oriented, abstraction based model. It’s also worth noticing that these giant companies therefore grew to their size while selling sub-optimal products or services.
So why use Interfaces? – On time to market.
This is where my argument in favor of writing interface driven code gets to take it’s turn. I’ll turn away from justifying the cost of interfaces, and towards the benefit of using them. You see, as I mentioned above, writing interface driven code does take longer due to the additional typing and red-tape required.
A while ago a friend issued me with a challenge, based on a claim that I’d made, he asked me to demonstrate that I could write some code to render a scene in 3D entirely without the benefit of modern 3D programming API’s or libraries. The details of the challenged don’t matter too much, except to say that this wasn’t about writing a fully fledged graphics engine. No, instead, write the code to render a rotating shape (cube f.x.) with shading and possibly with texturing. I was confident that I could meet this challenge, though I didn’t mention it at the time, because I’d done it before. I wrote code like this for fun in the good old days before the existence of dedicated 3D graphics hardware. So I set about writing the code, but I also added my own twist on the challenge. First I’d write it by simply sitting at the keys and typing it out as a long method, or handful of methods, and then I’d write it again using an interface driven abstraction.
The results however are what were very interesting to me. Performance wise, there was a small but notable decrease in performance for the interface driven code. This was not a surprise to me, given all of the indirection costs I mentioned above. Despite this, both applications performed sufficiently well as examples. I’d certainly have optimized away the interface driven design were I writing a real graphics engine, but it didn’t matter in this demo case. What did matter was how long it took for me to write the code in each case. The “straight” code took around 5 hours to write, while the interface driven code took me around 20 hours to write. Just in case anyone reading this can’t do the simple math, but also to put some emphasis on it, that’s FOUR TIMES as long to write the interface driven code!
Am I doing a great job of selling you on interfaces yet? Okay, well calm down for a moment and let me soothe this wound a little. You see, I am at least a little pragmatic about when to use interfaces and when not to. The whole point of this article is to explain that I understand when interfaces make sense, when they do not, and most importantly to explain this understanding to you, such that you might also make informed choices.
You see, the value of interfaces are in reuse, refactoring, and in good citizenship with other team mates.
I’ve heard it said many times that interfaces do not make code easier to work with, they make the code more confusing. I understand this argument having been through the process of learning to write interface driven code. What I also see time and time again, are developers that have truly adopted interface driven development, stating that the costs are worth it, that code becomes easier to manage and maintain. I’m among these of course. So how do we explain this disparity? Well, interface driven development truly is something that you must invest in, and become strongly familiar with, before you can appreciate it’s benefits.
Reuse
In my own personal code base I have large amounts of interface driven code which I use repeatedly. Just like any other code, once written, you may reuse it. The big difference with interfaces is that they force you, as you’re writing the interfaces themselves, to consider how your code will be used (by your future self, or by others). While you can’t possibly account for every future unknown scenario in which your code may be used, you can at least consider those possibilities.
Sometimes, it makes sense to just open up your IDE and start bashing out code until you have something that works. I get it, it’s an efficient way to try something, and as per my anecdote above, it can be four times ( or more ), faster than writing interface driven code. However, I rarely do this anymore. You see, a bunch of code written up inside a single function or method, or just a handful of such functions or methods, is not particularly reusable. You may be able to go back and copy & paste out some useful pieces, modify them to fit your new use scenario, and continue bashing out code – but as you’ll be aware, this way demons lie. Copy-pasted code is prone to error, and, does nothing to lend it’s self to being reused within the same project. You may well end up with duplicated code within your project this way. While it’s true that duplicated code is not necessarily a bad thing, it does lead to code which is more difficult to manage, and where there is replication of source, there is potential for replication of bugs too.
Interfaces give you the same opportunities that object classes do for code reuse, while forcing you to consider how to make generic, reusable code, and also forcing you to think about how consumers of your code will interact with it. This is the contract enforcing nature of interfaces, and when you’re practiced with them, you will notice how much easier it is to build projects that reuse the code you previously put behind these interfaces. What’s more, interfaces free you from some of the evils of object oriented code…
Refactoring and Inheritance
I’ve spent around 20 years writing software for commercial employers now. For the majority of this time, writing object oriented code, I’ve felt that something was just wrong about the whole process. It took me a few years to whittle down just what it was, but something about object oriented code just didn’t make sense. The problem, was that of inheritance.
When I first started sharing my concerns on this problem, I’d describe it by saying that I felt that Object Oriented Programming was a “miss-step” in the software development industry. This was seen as quite a controversial view point, and it certainly upset some Delphi programmers. Delphi, with it’s VCL framework and component driven design, depends heavily on the Object Oriented Programming model. It’s one of the tools strongest features, and of course, seasoned Delphi developers thank Object Oriented Programming for a lot of their successes. The immediate reaction that you tend to get from a Delphi developer when you suggest that there is something wrong with OOP, is a look of horror, with the stress lines of “Procedural Programming”. It would be akin to telling a pilot that wings are a bad idea, and that perhaps we should use hot air balloons to get around the planet.
So what did I do to avoid the look of horror on those faces? Well, I shut up. I quietly continued feeling the irritation of something that was so obviously bad to me, without looking in any more detail at what the true cause of my concern was. Until that is, I started noticing others in the development community coming around to the same conclusion. You see, there are several good, sound ideas in OOP, but the problem child of this style of programming is inheritance. Finally, after all these years, other developers were starting to come around to my way of thinking, and better yet, they’d pin-pointed the cause of my discomfort.
Inheritance in OOP is intended to provide for the ability to composite reusable pieces of code. You write a piece of code into a class, with some functionality that might be useful to reuse, then you’re able to descend that class to make a new one which “inherits” the code from the first. Typically, this idea is described to newcomers with somewhat trite examples such as, a circle, a square and a triangle all have something in common, they’re all a ‘shape’, so we write a class which understands how to be a shape, and then we can descend it to specialize that code on a particular shape.
Well okay, but lets say you’re writing software which represents spare parts that are available from an auto-manufacturer. What does a steering wheel have in common with an exhaust manifold? Conceptually, they are both “parts” and they may also both be “inventory items”, but that’s pretty much where their similarities end. Consequently, when writing this software using inheritance, we’re forced to come up with contrived similarities between these objects, and in fact, often we are forced to use synonyms of the word “object” to do it! How many times have you come across “items” or “objects” or even extend it out to “inventory items” or “order items”, everything in OOP has become an “object” or an “item” or a “part” or a “thing”!
Interfaces don’t necessarily free you from this synonym of thing problem, but what they do, is free you from the cause of it. You see, inheritance doesn’t act merely as a means of compositing code, but instead, it imposes on you a hierarchy of classes. You can’t inherit something if you don’t have an ancestor right? So if you want to use inheritance to provide compositing, you’re going to have to come up with a hierarchy for every “class” of object within your code. Interfaces are different, one object may implement multiple interfaces, and those interfaces need not be derived from other interfaces, they may be stand-alone. It would be fine for any object to implement the “IInventoryItem” interface, while also implementing an interface which represents something entirely different. The abstraction provided by classes is maintained, while the hierarchical inheritance constraint is lifted.
When you become familiar with using interfaces, it leads to a paradigm shift in the way you think about designing objects, or at least it did for me, and I’ve heard others making claims that lead me to think it did for them also. It goes a little something like this. If you want to impose that code derived from some base class behave a particular way, you do so by writing abstract virtual methods. That-is, you write methods which the descendant class must implement in order to specialize the functionality. When considered from the position of the new class, this is a bottom up approach, because as you descend the ancestry of the class, the functionality comes from ever lower in that tree. Interfaces act the opposite way, the imposition of constraints is written into the interface, and this is imposed on every class which implements this interface, regardless of the ancestry of that class. To word it another way, when you look at a class you don’t know from where each of the pieces of its functionality came, but when you look at an interface, what you see is what you get.
Refactoring and Dependency Injection
Dependency Injection is a bit of a fancy name for something you’ve probably been doing already with classes. When you pass a reference to a class (or interface) into a function or method as a parameter, that is essentially dependency injection. Essentially, your function or method is able to take advantage of the functionality of the class or interface that has been passed to it.
Perhaps a more common case for dependency injection however, is at the object level. When you instance a new object, you may pass functionality in the form of an object or interface reference, to the constructor of the new object. That new object retains a reference to the object that was passed in, and is able to make use of its functionality internally.
When you do this using a class, your new object understands the functionality available via the injected class, but there’s an additional constraint. As mentioned above when discussing inheritance, your object must be of the type expected by the function parameter, or descended from that type. That is, if your method expects an “inventory item” to be passed in, well then the class you pass must be descended from the inventory item class. With interfaces however, the inheritance of the object being passed in, is entirely irrelevant, so long as the object implements the interface.
That may take a little thought if you’re not already familiar with interface driven development. So let me try to help clarify. Suppose I have an object that is of class “Steering_Wheel” and another of type “Exhaust_Manifold”, neither is inherited from “Inventory_Item”, in fact, steering wheel is descended from “Interior_Parts” and “Exhaust_Manifold” is descended from “Engine_Parts”. They’re entirely unrelated objects. If we wanted to pass these to a method which expects an “Inventory_Item” we’d have to descend each of them from that same class, but with interfaces, we do not have this constraint. So long as both “Steering_Wheel” and “Exhaust_Manifold” implement the “IInventoryItem” interface, we can write a single function which takes an “IInventoryItem” as a parameter, and we can pass either to it, regardless of their ancestry.
What does this mean for refactoring? Well, the results are broad, but here’s just one example. Sticking with the auto-parts example, lets suppose you have a tool that is used by the auto servicing department. You track this tool as an asset, but it’s not an item you sell and so it’s not a part of the inventory. The decision has been made that you’re going to begin stocking this tool in the inventory, but it’s not descended from Inventory_Item. Oh no! With the inheritance model you now either have to write a new class which descends Inventory_Item, or you have to alter the inheritance of your existing “tool” class, which is already tightly bound to its ancestry as an asset class. With interfaces, this is far less of a problem, you just have to ensure that the “tool” class implements the “IInventoryItem” interface, without being concerned about altering its ancestry otherwise.
This is of course, quite a contrived example. You probably would never have written your inventory system this way to begin with. I get that, I’m using this example really only on a surface level. It’s quite difficult to explain the paradigm shift that takes place when you begin working with interface driven code, but I hope the example I’ve given here is sufficient to have sparked that mental shift for you. If not, there’s a great resource for you. This video by “CodeAesthetic” on YouTube does a far better job of explaining the problems of inheritance and the benefits of interfaces than I feel I’ve done here..
“The Flaws of Inheritance – Code Aesthetic.”
Regardless of whether or not you’ve understood me, go watch this video and give it a like and a subscribe, you’ll not regret it with the quality of the videos produced on this channel!
The ARC problem
There are many that don’t like memory managers at all, and I want to tell you that I totally understand where you’re coming from. Way back in the days of old, before we used Garbage Collectors, or ARC (Automatic Reference Counting) memory management, or any other kind of memory safety, we as developers all knew one thing. It was our responsibility to free up the resources we’d allocated. Oh how I miss those good old cowboy days. We’d repeat little mantras to ourselves like “That which creates, destroys” in order to remember where in the code we were responsible for disposing allocated memory.
Well, those days, rose tinted as my retrospective vision for them is, had issues. During the 90’s the “Access Violation” error message, fed from the Windows Operating System when a developer forgot to free, or used a freed object, was so common it was practically a household term. Software was booming, and employers were hiring entirely unqualified fools such as myself to fill the demand for developers. It was a rough-shot time, mistakes were made, and there were those that felt something had to be done about this! Thus, as compiler vendors tried to keep up with the pace of growth in the software industry, they did so by providing “useful” features such as memory management systems to help us get it right.
I have thankfully never had to do much work under the supervision of a Garbage Collector proper, though I have written a mark-and-sweep based collector myself on one occasion, and so I have a basic understanding of how they work. The problem with garbage collection unfortunately, is that it’s difficult to know on a source code level, where the garbage collector might kick-in and begin one of it’s sweeps. Garbage collectors are therefore not a great option in many cases, particularly in performance critical code.
ARC is better, though I won’t claim it to be perfect. ARC is at least deterministic, in that if you craft your code carefully, you can indeed know when a de-allocation will take place. It’s at the point that the “owning” reference is disposed. Now, of course I said “if you craft your code carefully” with good reason. ARC has it’s own problems, such as keeping objects in memory after you believe they were released (the cyclic reference problem). I’m actually a fan of ARC, though just as with interfaces, I am measured about when to use it, and I try to be careful. I utilize the “retained object” feature of ARC pointers to ensure that things remain in memory long enough, I am careful to understand when objects should be freed, and I try to prevent the consumers of my code from gaining strong references to objects which might enable them to retain objects longer than my code expects. ARC is a bit of a beast, and offers many opportunities for mistakes, but it can of course be used effectively when used with care.
Again, just as with interfaces themselves, ARC is not something that I think fits into every case, but it is a feature that I really appreciate in many cases, and it’s actually one of the reasons I use interfaces to begin with. The interface driven list collection I mentioned earlier, has a great advantage for me. I know that when I free my list, I need not concern myself with freeing the storage behind the items in the list, because they too are reference counted. I know that when I write “List := nil;” ( “List = null;” ), the entire thing will be disposed, items and all, and that all of the allocated memory is returned to the system.
One of those rules that I adhere to when working with reference counting, just as I’d had rules for remembering to free memory under a non-managed model, is to never use weak references. Unsafe references, yes, sometimes, but never weak. Not only do weak references cause a performance cost, but I’ve come to think of them as an unnecessary feature, and one that encourages bad practice. That’s a whole other argument, which I won’t delve into here, but suffice to say, I don’t use weak references, and thus, avoid the performance costs associated with them.
Conclusions
So then, It’s time for me to wrap this up.
I love interfaces, but I know that they have limitations, constraints, and performance concerns. While the opinionated fever of developers in social media and blogs tends to be either absolute or else pragmatic, I don’t feel either is necessary in this case. I don’t need to say that you should absolutely use interfaces, or that you absolutely should not. Nor am I being pragmatic in capitulating to those two extremes at the same time. No, Interfaces are a compiler feature that has its uses, and just like any other feature, it’s constraints. We should be measured about when to use them, and when not to.
Where I will show leaning is that I feel that interfaces are not only a good option for cases in which you have multiple implementations, but that its a good idea to use them even if you have only one implementation. Of course, I understand that there are exceptions to this rule – I wouldn’t recommend using interfaces as the basis for designing the critical loop of your game engine, or database engine, but rather, that for the majority of general application development their performance is sufficient, and their benefits worth the trade off. What benefits? Those of being able to reuse and more easily refactor your code.
The benefits of being able to de-couple regions of your code entirely behind interfaces are such that when the time comes to refactor a feature, you’ll be able to do so far more easily. It may have taken longer to write those interfaces in the first place, due to all the extra typing, but those interfaces provide a logical barrier to entire regions of code. You may swap out the implementations of these interfaces without concern for “breaking it elsewhere”. There is no better approach to any problem than to keep your options open for as long as possible, and this is what interfaces will do for you.
I hope it’s clear that I really don’t have a “dog in this fight” so to speak, when it comes to your use of interfaces as a feature, that’s up to you. What I’m hoping to express is that from my own experience, this is a valuable feature to use, so much that I use it very often. I encourage you to try using interface driven design for new code, but also, to consider sliding interfaces into your existing code base. If you have one of those particularly large code bases, in which any change appears to break something unrelated, I am confident that the benefits of interfaces will become apparent. As you move code behind interfaces, your code becomes more loosely coupled, and you’ll find that breaking things becomes less frequent.
Most critically however, interfaces are one of those tools that you can use to fight the evils of object inheritance. If you’ve not yet identified inheritance as an evil, then that’s all the more reason for you to really give interfaces an honest try. It’s not uncommon that I hear developers using interfaces say things like “I just don’t use inheritance anymore.” I understand this sentiment, I don’t use inheritance anymore either, my interface driven code has meant that I don’t have to. In fact, I did use inheritance recently because it seemed convenient at the time, and now I have around a dozen units of code that I intend to refactor in order to remove that inheritance!
If nothing else, I hope that this article has given you food for thought.
Thanks for reading!
Interfaces have been around for a very long time, both in our beloved Delphi pascal, but also in many other language compilers. Despite them having been around for so long, I still see a lot of resistance to using them. Not only do I see resistance, but often the resistance appears to be based on a misunderstanding of what interfaces actually offer. I just got done writing up an article on the costs and benefits of interface driven design, in general, and specifically in Delphi.
Read it here.